The first parts of the tutorial will cover Sync Services for ADO.net. They work similar to but they extend the sync runtime and provide some providers for databases. Read part 1 for an introduction to Sync Framework.
The basics
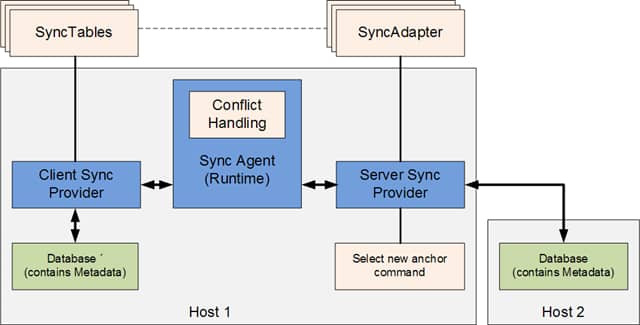
The sync agent is the runtime which takes the two providers. The client provider has a set of sync tables that specify which tables on the server it would like to synchronize. You specify if the table is created on the client and how, the type of synchronization (e.g. download only, bidirectional…) and wether or not it belongs to a sync group.
(Sync groups specify groups of tables that are analyzed and synchronized in accordance to foreign key constraints.)
The sync adapters specify which columns on the server database tables are used for tracking changes and the sync options. They describe how data is synced.
The server provider also needs a set of commands, one of them being the new anchor command which specifies how to retrieve a new anchor on the server side.
The database
In the diagram you can see that there the data store and metadata are one components (instead of two as shown in the last part). This means you are tracking the metadata (change tracking) in the data store itself. In this concrete scenario there are additional columns in the tables that specify when something was added, changed or deleted and who did it.
This is next step in the tutorial. Preparing the server database for synchronization.