In the first and second part of the tutorial I gave an overview on the Microsoft Sync Framework and the Sync Services for ADO.net. What it can do for you, what tools you are given and now we are going to take a look at the first set of providers that Microsoft has written.
The Sync Services for ADO.net let you synchronize data between databases. It’s a common requirement for online/offline scenarios. I’m sure a lot of people have used RDA in the past. Now SSA provides a simple way to achieve such scenarios.
Prerequisites
You need to install the the Sync Framework (as of writing available in CTP1 Refresh) and the Sync Services for ADO.net. Both are available here.
Additionally you need the SQL Server Compact Edition (formerly Everywhere Edition, current Version 3.5). If you have Visual Studio 2008 installed the libraries required are installed as well.
For the server part of this tutorial I have used SQL Server Express Edition.
The demo project
As a demo for the first part of the tutorial I have created a small time tracking application. You can track user’s time spent on different projects.
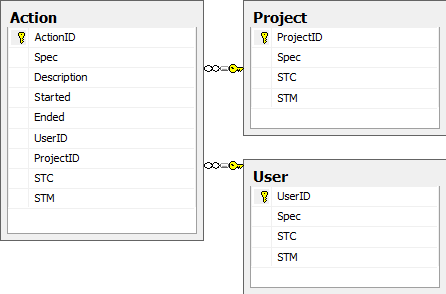
The project has a simple database schema, shown above. It’s the normal way I would design such a database, except for two things. The primary key chosen here is a Guid. In such simple examples I would usually use an integer, but since I knew it was going to be a replication scenario I chose a unique identifier (see below for some explanation) and secondly I usually automatically include a timestamp column (called timestamp) in addition to the datetime columns STC, STM (system-time created, modified). Read on to see why I left it out.
The client is a simple GUI for entering and viewing data.
Preparing the database for synchronization.
(A lot of more detailed information on the topics covered here can be found in the Sync BOL.)
I will go for a maximum of flexibility in this tutorial and will enable bidirectional inserts, updates, and deletes with conflict detection. To do this your database needs to fulfill a few properties:
Primary Key of unique column: This sounds fairly normal. Any good database design has a unique PK, but you may have encountered a lot of integer primary keys. These are great for local systems, easy to use and great for writing manual sql statements. But for a replication scenario you can’t really sync a sequential integer key very well because it has a state (the sequence). You need a globally unique ID. SQL provides the type uniqueidentifier which is ideal for this.
Side-note: A lot of people might argue against using Guids, the main reasons usually being a performance hit (Guids are not sequential, so the row may not be inserted at the end of the table page), a maintenance hit (ever tried writing a lot of sql statements that lookup guid columns) and other impacts.
My point of view is that you can counteract a lot of the impacts and personally the prime example for synchronizing data is the Active Directory, which uses a Guid as it’s object Guid. But check out the BOLs for a number of alternatives.
In the example db, the primary keys are all unique identifiers. I have chosen to use NEWSEQUENTIALID() as a default - instead of NEWID() - to ensure a sequence when inserting rows locally (it has a privacy trade-off though, read about it here and it will not help us when the client syncs it’s of out sequence data to the server).
Side-note: What if you already have data in your database.
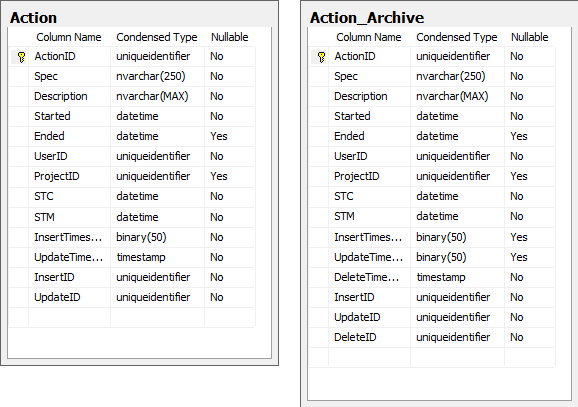
Track update time and track insert time: In SQL you can add a timestamp column to each row which will update on every change. Great, so this is your update time. But what about the insert time? Well add another timestamp. Wait, SQL won’t let you do this (and you can’t actually tell SQL not to update the timestamp field - I don’t actually know why). So the BOLs suggest adding a Binary(8) column and put a timestamp field in there. Can’t think of anything that’s wrong with that, so we’ll just go ahead an do that.
Track delete time: Sounds similar to the above, but once the row is deleted you can’t really use the deleted column of the table. So we create something Microsoft calls a tombstone table. I personally have seen the word archive more often but they basically talk about the same thing. You have a live table with data that is still alive and then you have a dead table where all you deleted table lives. (Some people might actually go so far as to include a pregnant or premature table, to include data that is not alive yet - tax rates for some future time - but others opt for specifying a validity time range in the live table for this case. But this is a topic for another post.)
In our example we create an archive table for each table that we would like to sync. They are almost identical to the live table. BOLs suggests removing the insert and update time columns and adding a delete column. I personally wouldn’t do that because you are losing information that you may need in an enterprise scenario (i.e. auditing). Keep the insert and update columns, just turn the update column into a bigint column like the insert, and add a timestamp column as the delete time column.
Then you need a trigger to catch deletes to the live table and write them to the tombstone table. Nothing spectacular here, check the BOLs if you need advice.
CREATE TRIGGER [dbo].[TRI_Action_Delete] ON [dbo].[Action] FOR DELETE
AS
BEGIN
SET NOCOUNT ON
DELETE FROM [Action_Archive]
WHERE [ActionID] IN (SELECT [ActionID] FROM deleted)
INSERT INTO [Actions].[dbo].[Action_Archive]
( [...] all columns [...] )
SELECT
[...] all columns [...]
FROM deleted
SET NOCOUNT OFF
END
Track client ID for inserts & Track client ID for deletes: As to not piggy-back changes that a client made back to the client you need to keep track of who made the change. Each client in the sync framework has a client id and you can track this by adding a InsertID, UpdateID and DeleteID to the respective tables.
In an enterprise database you may already have similar columns to comply with auditing rules and may be able to re-use those columns.
Indexes
The BOLs include some advice on creating indexes on the tables. For now you can ignore them but in a production environment you will speed up your data synchronization considerably by adding the appropriate indexes.
Summary
So far we have (only) prepared the server-side database for synchronizing with another database. This is probably about 50% of the work need to be done. In the next part we will take a look at the code that uses the Sync Framework.